
Kafka tổng hợp (Phần I): Tổng quan Kafka architecture
Loạt bài này mình sẽ nói về Kafka và chưa rõ nó sẽ gồm bao nhiêu phần cả . Ở bài này mình sẽ tổng hợp một số điều cần lưu ý ở Kafka architecture, đủ để có thể sử dụng được Kafka. Các phần sau sẽ đi sâu hơn nữa và thực hành một số kỹ thuật ở Kafka.
Kafka là gì
Apache Kafka is a publish/subscribe messaging system designed to solve this problem. It is often described as a “distributed commit log” or more recently as a “distributing streaming platform.”
Kafka là một nền tảng phân phối message(log) phân tán, phát triển theo model pub/sub. Producer được dùng để đẩy data vào Kafka, còn consumer được dùng để đọc data từ Kafka.
Topic, Partition trong Kafka

Kiểu dữ liệu trong Kafka được gọi chung là message. Các message này được lưu trữ tuần tự trong các topic. Mỗi message sẽ được đánh số thự tự gọi là offset. Có thể phân chia lưu trữ message trong topic ở nhiều partition, điều này cho phép scale horizontally topic ở Kafka dễ dàng giúp tăng tốc độ xử lý của hệ thống.
Khi chia topic thành nhiều partition thì thứ tự message chỉ được đảm bảo ở từng partition. Cho nên với các hệ thống cần xử lý đúng tuần tự message ở một topic thì không nên chia thành nhiều partition.
Message ở Kafka sẽ được lưu trữ ở file và sẽ không bị xóa, nên khi Kafka bị khởi động lại thì message vẫn sẽ được giữ nguyên.
Producers
Producers được dùng để đẩy message vào Kafka. Có 3 phương thức để đẩy message:
- Fire-and-forget: Với phương thức này khi gửi message, producer sẽ không quan tâm là đã gửi thành công hay chưa và producer sẽ cố gắng gửi lại message tự động. Tuy nhiên sẽ không kiểm soát được việc message thỉnh thoảng bị mât không được lưu trữ vào Kafka.
- Synchronous send: Với phương thức này khi gửi message, producer sẽ đợi phản hồi từ Kafka xem message này đã được ghi hay chưa. Bởi vì phải đợi phản hồi từ Kafka nên với cách này tốc độ ghi message sẽ bị giảm.
- Asynchronous send: Với phương thức này khí gửi message, producer sẽ để lại một callback cho Kafka, sau khi thực hiện lưu message Kafka sẽ phản hồi vào hàm callback này. Producer sẽ không cần đợi phản hồi từ Kafka mà sẽ tiếp tục ghi tiếp giúp đảm bảo tốc độ ghi được nhanh chóng mà vẫn kiếm soát được việc mất message.
Khi deploy Kafka có nhiều bản replicas cần lưu ý thêm tham số acks:
- acks=0: Producer sẽ không đợi phản hồi từ Kafka xem message đã được ghi thành công hay chưa.
- acks=1: Producer sẽ đợi phản hồi từ Kafka xem message đã được ghi thành công ở lead replica hay chưa, nếu chưa thì producer sẽ gửi lại message tránh việc mất message.
- acks=all: Producer sẽ đợi phản hồi từ Kafka xem message đã được ghi thành công ở toàn bộ các replica hay chưa. Điều này sẽ giúp đảm bảo việc kiểm soát được message nhưng sẽ làm chậm tốc độ ghi của producer.
Với topic được chia thành nhiều partition, mặc định producer sẽ ghi message lần lượt chia đều vào các partition theo cơ chế round-robin. Cũng có thể chỉ định message sẽ được ghi vào partition cụ thể.
Consumer và consumer group
Consumer được dùng để lấy message từ Kafka, một consumer có thể lấy message từ nhiều topic. Có thể nhóm các consumer thành một group để tăng tốc độ đọc message từ các partition của topic.
Có hai kiểu để phân chia các partition cho consumer:
-
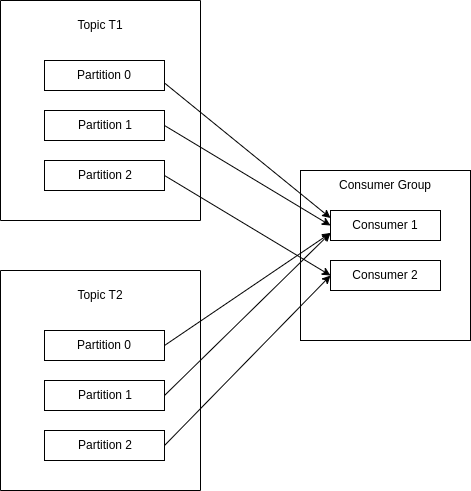
Range: Gán cho consumer các partition liên tiếp. Ví dụ: có 2 topic T1, T2, mỗi topic có 3 partition và 1 consumer group gồm C1, C2. Thì C1 sẽ được gán partition P0, P1 của T1 và T2 còn C2 sẽ được gán P2 của T1 và T2. C1 được gán nhiều partition hơn do số lượng parition đang không chia hết cho tổng số consumer.
-
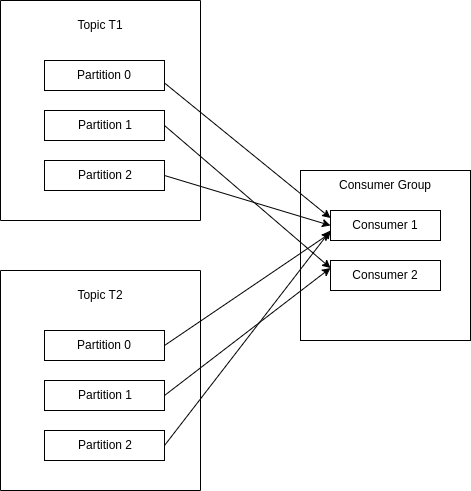
RoundRobin: Gán tuần tự partition cho consumer tuần tự, từng cái một. Ví dụ: có 2 topic T1, T2, mỗi topic có 3 partition và 1 consumer group gồm C1, C2. Thì C1 sẽ được gán parition P0 vs P2 của T1 và T2 còn C2 sẽ được gán P1 của T1 và T2.
Consumer không thể push message như RabbitMQ nên Kafka không được dùng cho service integration.
Commit
Khi consumer pull message từ topic, cần đánh dấu đã nhận message để Kafka có thể quản lí được message nào đã được đọc bởi consumer. Có 3 cách để làm điều này:
- Auto commit: Với option này cứ 5s(có thể điều chỉnh), consumer sẽ commit offset gần nhất mà client nhận được khi pull message. Vì cách này sẽ không kiểm soát được logic code sau khi nhận được message có thực hiện thành công hay chưa nên đôi khi sẽ dẫn đến message đã bị đánh dấu là đã đọc nhưng vẫn chưa được xử lý đúng.
- Sync commit: Khi client call hàm
commitSyncsẽ đánh dầu offset mới nhất nhận được khi pull message và sẽ đợi Kafka phản hồi thành công thì mới thực hiện message tiếp theo. - Async commit: Tương tự như Sync commit chỉ khác là sử dụng hàm này sẽ không cần đợi Kafka phản hồi mà vẫn tiếp tục thực hiện message tiếp.
Ngoài ra do pull message có thể trả về nhiều message cùng một lúc, nên có thể commit
một offset cụ thể bằng cách truyền thêm param vào hàm commit: commitAsync(currentOffsets, null)
Ref:
- Neha Narkhede, Gwen Shapira & Todd Palino. Kafka: The definitive guide